오늘은 데이터베이스(DB)에서 사용되는 주요 자료구조에 대해 알아보겠습니다. 효율적인 데이터 관리와 빠른 검색을 가능하게 하는 자료구조들은 데이터베이스의 성능과 직결됩니다. 데이터베이스는 대량의 데이터를 효율적으로 저장하고 관리하기 위한 시스템입니다. 이러한 시스템에서 자료구조는 데이터의 저장 방식, 검색 속도, 업데이트 효율성 등에 큰 영향을 미칩니다. 적절한 자료구조를 선택함으로써 데이터베이스의 성능을 극대화할 수 있습니다. 이제 주요 자료구조들을 하나씩 살펴보겠습니다.
B-트리 및 B+트리
B-트리
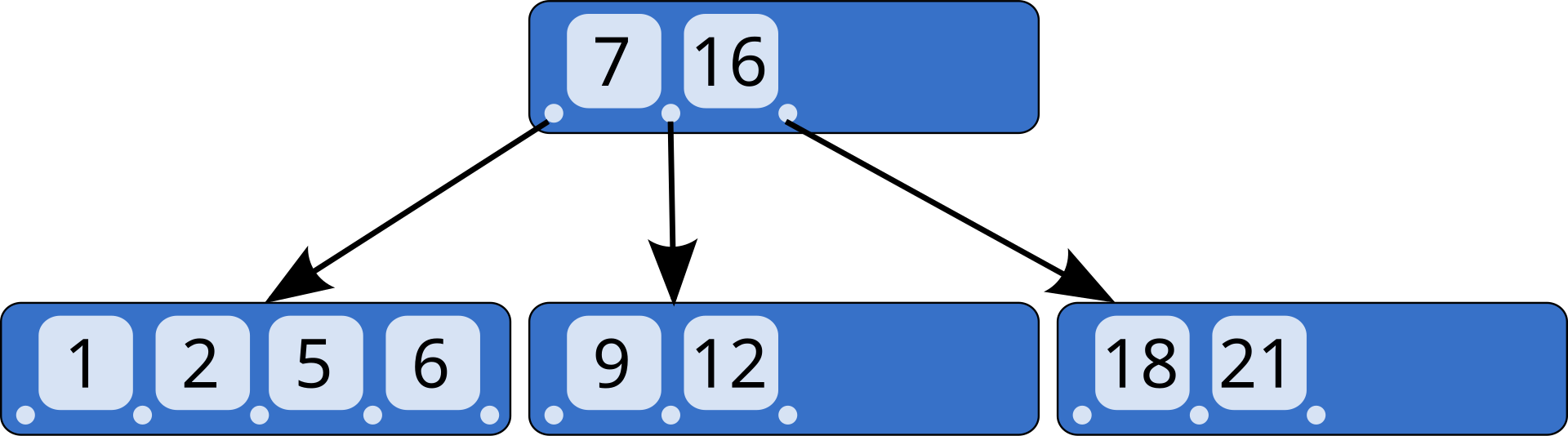
출처: https://ko.wikipedia.org/wiki/B_%ED%8A%B8%EB%A6%AC
B 트리 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. B 트리 (Bayer & McCreight 1972) harv error: 대상 없음: CITEREFBayerMcCreight1972 (help) (Knuth 1998) harv error: 대상 없음: CITEREFKnuth1998 (help) Order 5. 전산학에서 B-트리(B-tree)는 데이
ko.wikipedia.org
B-트리는 균형 잡힌 트리 자료구조로, 데이터베이스 인덱싱에 널리 사용됩니다. 각 노드는 다수의 키와 자식을 가질 수 있어 디스크 접근 횟수를 줄일 수 있습니다. B-트리는 삽입, 삭제, 검색 연산에서 모두 로그 시간 복잡도를 가집니다.
장점:
- 높은 디스크 효율성: B-트리는 한 노드에 여러 키를 저장하기 때문에 디스크 블록의 활용도가 높습니다. 이는 디스크 접근 횟수를 줄여 성능을 향상시킵니다.
- 균형 잡힌 구조: 모든 리프 노드가 동일한 깊이를 가지므로 최악의 경우에도 예측 가능한 성능을 보장합니다.
- 동적 데이터 삽입 및 삭제 지원: 데이터의 추가와 삭제가 빈번한 환경에서도 효율적으로 작동합니다.
단점:
- 복잡한 구현: B-트리는 단순한 트리에 비해 구현이 복잡하며, 특히 노드 분할과 병합 과정이 까다롭습니다.
- 메모리 사용량: 각 노드에 여러 키와 포인터를 저장하므로 메모리 사용량이 증가할 수 있습니다.
- 읽기/쓰기 오버헤드: 노드 단위로 데이터를 관리하기 때문에 작은 데이터 변경에도 전체 노드를 다시 읽고 써야 할 수 있습니다.
대표적인 데이터베이스 활용 사례:
- MySQL (InnoDB 스토리지 엔진): InnoDB는 B+트리를 사용하여 기본 및 보조 인덱스를 관리합니다. 이는 빠른 검색과 효율적인 디스크 사용을 가능하게 합니다.
- PostgreSQL: PostgreSQL의 기본 인덱스 타입인 B-트리 인덱스는 다양한 쿼리 최적화에 활용됩니다.
B+트리

출처: https://ko.wikipedia.org/wiki/B%2B_%ED%8A%B8%EB%A6%AC
B+ 트리 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 단순한 B+ 트리의 예 B+ 트리(Quaternary Tree라고도 알려져 있음)는 컴퓨터 과학용어로, 키에 의해서 각각 식별되는 레코드의 효율적인 삽입, 검색과 삭제를 통해 정
ko.wikipedia.org
B+트리는 B-트리의 변형으로, 모든 실제 데이터는 리프 노드에 저장되고 내부 노드는 인덱스 역할만 합니다. 이로 인해 범위 검색이 효율적이며, 리프 노드가 연결 리스트로 연결되어 있어 순차 접근이 용이합니다. 대부분의 관계형 데이터베이스 시스템에서 기본 인덱스 구조로 사용됩니다.
장점:
- 범위 검색 최적화: 모든 실제 데이터가 리프 노드에 위치하고, 리프 노드가 순차적으로 연결되어 있어 범위 검색 시 연속적인 리프 노드 접근이 용이합니다.
- 높은 디스크 효율성: 내부 노드는 인덱스 역할만 하므로 더 많은 키를 저장할 수 있어 디스크 사용이 최적화됩니다.
- 빠른 검색 및 업데이트: 로그 시간 내에 검색이 가능하며, 삽입과 삭제도 효율적으로 처리됩니다.
단점:
- 내부 노드의 추가적인 포인터 필요: 내부 노드가 인덱스만 담당하므로 포인터가 추가로 필요해 메모리 사용량이 늘어날 수 있습니다.
- 복잡한 구현: B-트리와 유사하게, 노드 분할과 병합이 복잡하며 구현이 까다롭습니다.
- 쓰기 오버헤드: 데이터 변경 시 리프 노드의 순차 연결 리스트도 함께 업데이트해야 하므로 쓰기 작업이 다소 복잡해질 수 있습니다.
대표적인 데이터베이스 활용 사례:
- MySQL (InnoDB 스토리지 엔진): B+트리를 사용하여 인덱스를 관리함으로써 효율적인 데이터 검색과 범위 쿼리를 지원합니다.
- SQLite: 기본 인덱스 구조로 B+트리를 사용하여 작은 규모의 데이터베이스에서도 빠른 성능을 제공합니다.
- Oracle Database: B+트리를 사용한 인덱스 구조를 통해 대규모 데이터 처리와 빠른 검색을 지원합니다.
해시 테이블
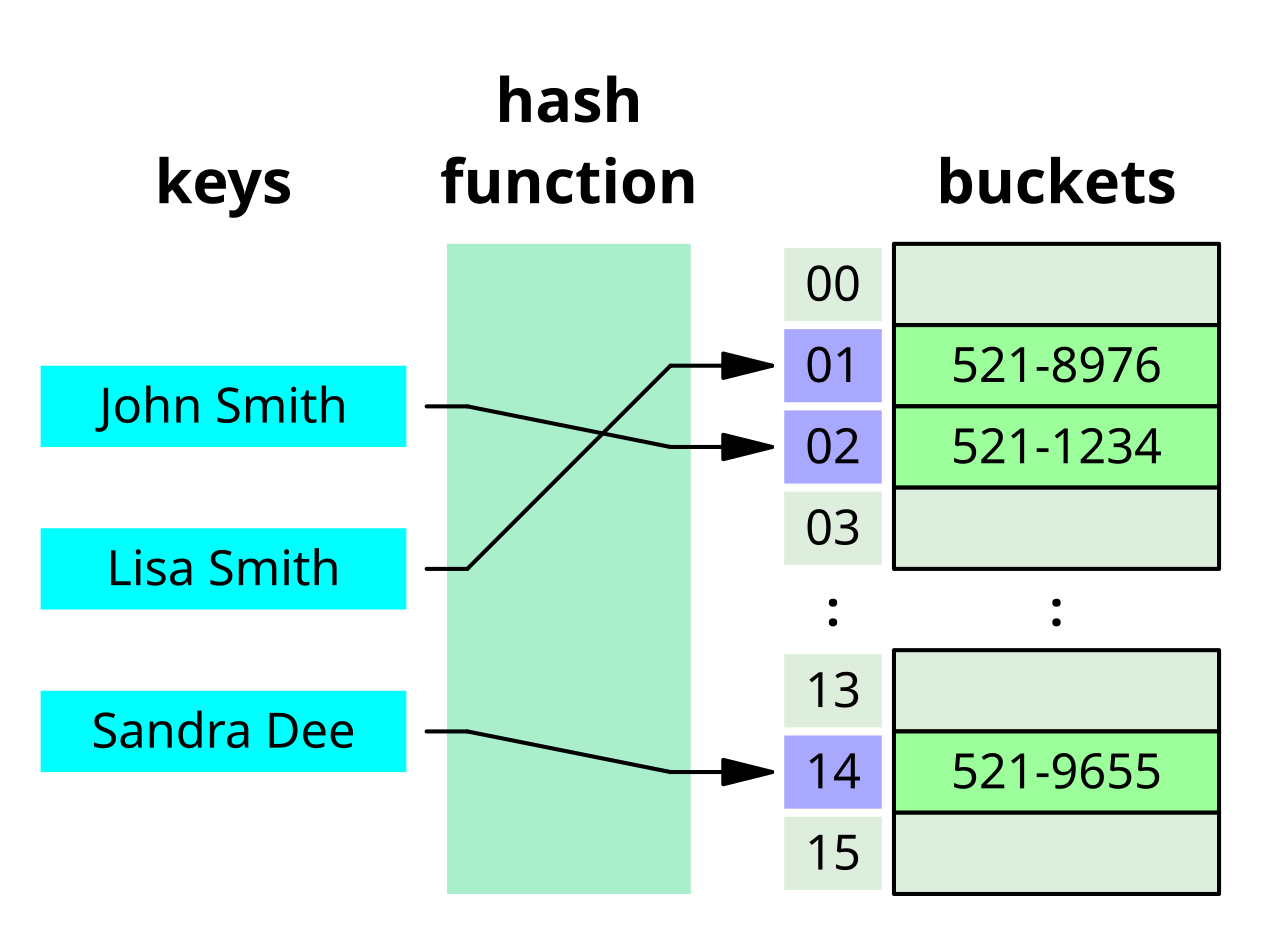
출처: https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%85%8C%EC%9D%B4%EB%B8%94
해시 테이블 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전.
ko.wikipedia.org
해시 테이블은 키-값 쌍을 저장하는 자료구조로, 키를 해시 함수에 적용하여 데이터의 위치를 결정합니다. 해시 테이블은 평균적으로 매우 빠른 검색 속도를 제공하지만, 범위 검색에는 적합하지 않습니다.
장점:
- 평균적으로 상수 시간의 검색 속도: 해시 함수를 사용하여 직접적으로 데이터에 접근하므로 매우 빠른 검색이 가능합니다.
- 단순한 구현: 기본적인 해시 테이블 구조는 비교적 간단하게 구현할 수 있습니다.
- 효율적인 메모리 사용: 키와 값만 저장하므로 불필요한 노드나 포인터가 없습니다.
단점:
- 충돌 관리 필요: 서로 다른 키가 동일한 해시 값을 가질 경우 충돌이 발생하며, 이를 해결하기 위한 추가적인 로직이 필요합니다.
- 범위 검색 비효율적: 해시 테이블은 키의 순서나 범위를 고려하지 않기 때문에 범위 검색에 적합하지 않습니다.
- 동적 크기 조정의 복잡성: 데이터가 증가하면 해시 테이블의 크기를 조정해야 하는데, 이는 비용이 많이 들 수 있습니다.
활용 사례:
- 캐시 시스템
- 키-값 저장소
대표적인 데이터베이스 활용 사례:
- Redis: Redis는 메모리 기반의 데이터 저장소로, 내부적으로 해시 테이블을 사용하여 빠른 키-값 접근을 제공합니다. 특히, HASH 자료형을 통해 복잡한 데이터 구조를 효율적으로 관리합니다.
- Memcached: Memcached는 분산 메모리 객체 캐시 시스템으로, 해시 테이블을 사용하여 키-값 쌍을 빠르게 저장하고 검색합니다.
- Cassandra: Apache Cassandra는 일부 내부 데이터 구조에서 해시 테이블을 사용하여 빠른 데이터 접근을 지원합니다.
비트맵 인덱스
비트맵 인덱스는 각 데이터 값에 대해 비트맵을 사용하는 인덱스 구조입니다. 주로 열의 값이 제한된 카디널리티를 가질 때 효과적입니다. 비트맵 인덱스는 빠른 논리 연산을 통해 복잡한 쿼리를 효율적으로 처리할 수 있습니다.
장점:
- 빠른 복합 쿼리 처리: 여러 비트맵을 논리 연산(AND, OR, NOT)으로 결합하여 복잡한 쿼리를 빠르게 처리할 수 있습니다.
- 압축을 통한 저장 공간 절약: 비트맵은 압축이 용이하여 저장 공간을 절약할 수 있습니다.
- 효율적인 집계 연산: 집계 쿼리에서 빠른 응답을 제공할 수 있습니다.
단점:
- 높은 업데이트 비용: 데이터의 삽입, 삭제, 업데이트 시 비트맵을 모두 수정해야 하므로 비용이 많이 듭니다.
- 높은 카디널리티 데이터에는 비효율적: 값의 종류가 많아지면 비트맵의 수가 증가하여 저장 공간과 처리 비용이 증가합니다.
- 복잡한 관리: 비트맵의 관리와 최적화가 필요하며, 이는 시스템의 복잡성을 높일 수 있습니다.
활용 사례:
- 데이터 웨어하우스
- OLAP 시스템
대표적인 데이터베이스 활용 사례:
- Oracle Database: Oracle은 비트맵 인덱스를 제공하여 데이터 웨어하우스 및 OLAP 응용 프로그램에서 효율적인 쿼리 처리를 지원합니다.
- IBM Db2: Db2는 비트맵 인덱스를 사용하여 복잡한 분석 쿼리를 최적화합니다.
- SAP HANA: SAP HANA는 비트맵 인덱스를 활용하여 빠른 데이터 검색과 집계 연산을 지원합니다.
트라이(Trie)
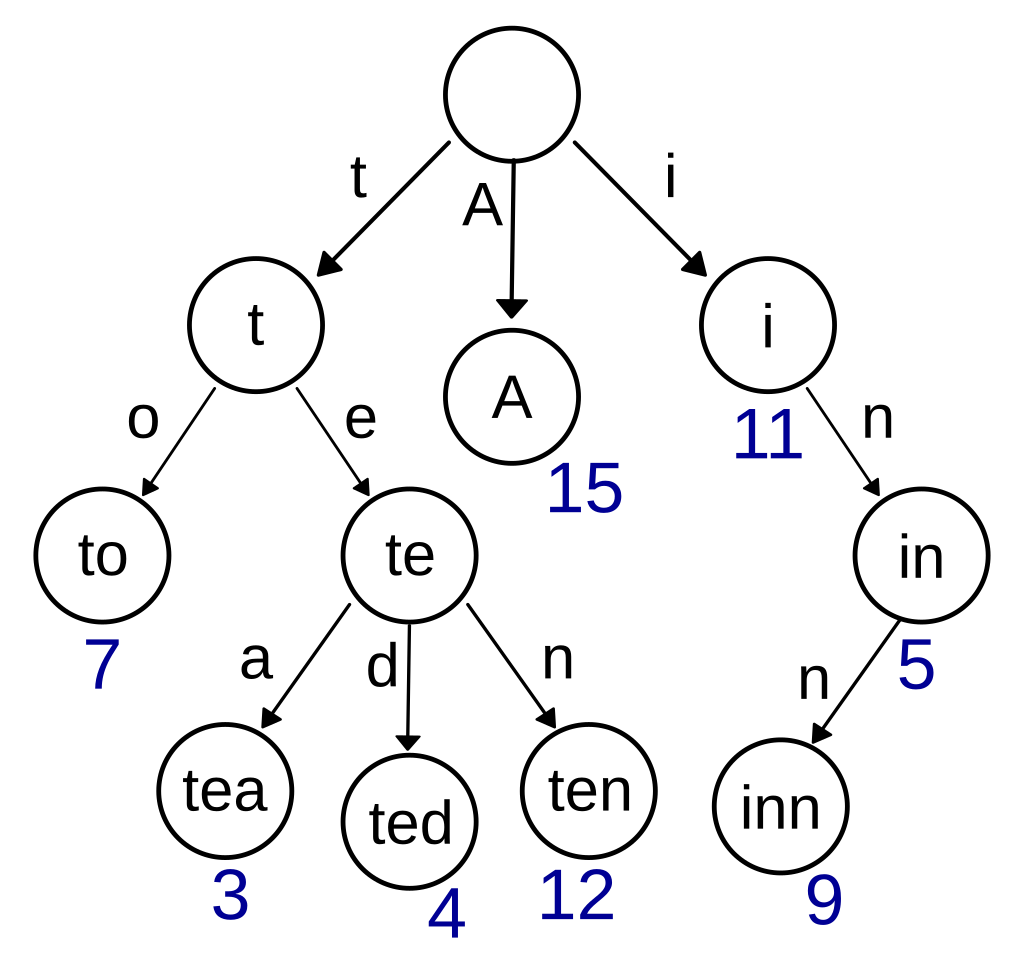
출처: https://ko.wikipedia.org/wiki/%ED%8A%B8%EB%9D%BC%EC%9D%B4_(%EC%BB%B4%ED%93%A8%ED%8C%85)
트라이 (컴퓨팅) - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. "A", "to", "tea", "ted", "ten", "i", "in", "inn"를 키로 둔 트라이. 이 예제에는 모든 자식 노드가 알파벳 순으로 왼쪽에서 오른쪽으로 정렬되어 있지는 않다. (루트 노드
ko.wikipedia.org
트라이는 문자열 검색에 특화된 트리 자료구조로, 키를 문자 단위로 분해하여 저장합니다. 접두사 검색, 자동 완성 기능 등에 효과적입니다.
장점:
- 빠른 문자열 검색: 문자열의 각 문자를 노드로 분해하여 저장하므로 검색 속도가 매우 빠릅니다.
- 접두사 기반 검색에 최적화: 특정 접두사를 가진 모든 문자열을 효율적으로 검색할 수 있습니다.
- 공유된 접두사 저장: 공통된 접두사를 공유하여 메모리 사용을 최적화할 수 있습니다.
단점:
- 메모리 사용량이 많을 수 있음: 각 문자를 노드로 저장하므로 메모리 사용량이 증가할 수 있습니다.
- 긴 키에 비효율적일 수 있음: 키의 길이가 길어지면 트리의 깊이가 깊어져 성능이 저하될 수 있습니다.
- 복잡한 구현: 트라이의 구현은 단순한 자료구조에 비해 복잡할 수 있습니다.
활용 사례:
- 검색 엔진의 자동 완성
- 사전 데이터 구조
대표적인 데이터베이스 활용 사례:
- MongoDB: MongoDB는 텍스트 검색을 위해 내부적으로 트라이와 유사한 자료구조를 활용하여 빠른 검색을 지원합니다.
- Elasticsearch: Elasticsearch는 트라이 기반의 분석기를 사용하여 텍스트 검색과 자동 완성 기능을 제공합니다.
- Microsoft SQL Server: SQL Server의 Full-Text Search 기능은 트라이와 유사한 구조를 사용하여 효율적인 문자열 검색을 지원합니다.
그래프 자료구조
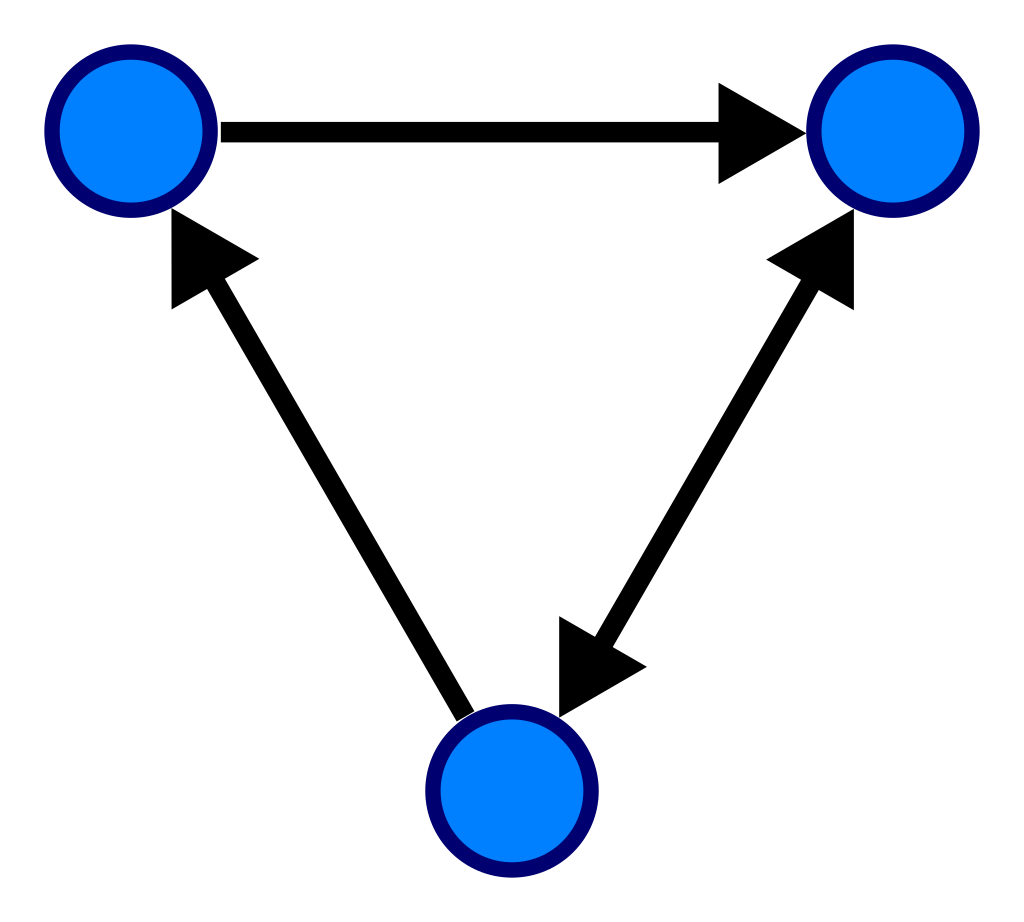
https://ko.wikipedia.org/wiki/%EA%B7%B8%EB%9E%98%ED%94%84_(%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0)
그래프 (자료 구조) - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 3개의 꼭짓점과 3개의 변으로 이루어진 그래프. 그래프(graph)는 vertex와 edge로 구성된 한정된 자료구조를 의미한다. vertex는 정점, edge는 정점과 정점을 연결하는
ko.wikipedia.org
그래프는 노드와 간선으로 구성된 자료구조로, 복잡한 관계를 모델링하는 데 적합합니다. 소셜 네트워크, 추천 시스템, 경로 찾기 등에 활용됩니다. 데이터베이스 내에서도 그래프 데이터베이스가 존재하여, 복잡한 관계 쿼리를 효율적으로 처리할 수 있습니다.
장점:
- 복잡한 관계 모델링 가능: 노드와 간선을 통해 다양한 관계를 직관적으로 표현할 수 있습니다.
- 유연한 쿼리 처리: 다양한 패턴의 쿼리를 유연하게 처리할 수 있어 복잡한 데이터 분석에 적합합니다.
- 빠른 탐색 성능: 특정 패턴이나 경로를 찾는 데 최적화된 알고리즘을 사용할 수 있습니다.
단점:
- 일반적인 관계형 쿼리에 비해 비효율적일 수 있음: 전통적인 SQL 기반 쿼리와는 다르게 작동하여 기존 시스템과의 통합이 어려울 수 있습니다.
- 특별한 쿼리 언어 필요: 그래프 쿼리를 위해 별도의 언어(Gremlin, Cypher 등)를 학습하고 사용해야 합니다.
- 높은 메모리 사용량: 노드와 간선의 수가 많아질수록 메모리 사용량이 급격히 증가할 수 있습니다.
활용 사례:
- 소셜 네트워크 분석
- 추천 시스템
- 내비게이션 시스템
대표적인 데이터베이스 활용 사례:
- Neo4j: Neo4j는 그래프 데이터베이스의 대표주자로, 노드와 간선을 기반으로 복잡한 관계를 효율적으로 관리하고 쿼리할 수 있습니다.
- Amazon Neptune: Amazon Neptune은 그래프 데이터베이스 서비스로, 그래프 자료구조를 활용하여 소셜 네트워크, 추천 시스템 등을 지원합니다.
- ArangoDB: ArangoDB는 멀티모델 데이터베이스로, 그래프 자료구조를 지원하여 복잡한 관계형 데이터를 효율적으로 처리합니다.
자료구조 선택
데이터베이스의 성능은 선택한 자료구조에 크게 의존합니다. 예를 들어, 인덱스를 B+트리로 설계하면 범위 검색이 빠르지만, 해시 테이블을 사용하면 단일 키 검색이 더욱 빠릅니다. 따라서 데이터의 특성과 사용 패턴을 고려하여 적절한 자료구조를 선택하는 것이 중요합니다.
고려 사항:
- 데이터의 크기와 카디널리티: 데이터의 양과 고유 값의 수에 따라 적합한 자료구조가 달라집니다.
- 예상되는 쿼리 패턴: 주로 어떤 유형의 쿼리가 수행될지를 고려해야 합니다. (예: 범위 검색, 단일 키 검색 등)
- 업데이트 빈도: 데이터의 삽입, 삭제, 수정 빈도가 높을수록 업데이트 비용이 낮은 자료구조를 선택해야 합니다.
- 저장 공간 제한: 메모리나 디스크 공간이 제한된 경우, 공간 효율적인 자료구조를 선택해야 합니다.
자료구조 선택의 예:
- 읽기 위주 시스템: 빠른 검색이 중요하다면 B+트리나 해시 테이블이 적합합니다.
- 쓰기 위주 시스템: 빈번한 업데이트가 필요한 경우, 해시 테이블보다 B-트리 계열이 더 적합할 수 있습니다.
- 복잡한 쿼리 시스템: 비트맵 인덱스나 그래프 자료구조가 유리할 수 있습니다.
데이터베이스에서 사용되는 다양한 자료구조들은 각각의 특성과 장단점을 가지고 있으며, 데이터의 특성과 응용 분야에 따라 적절히 선택되어야 합니다. B-트리와 B+트리는 범용적인 인덱싱에 적합하며, 해시 테이블은 빠른 키 검색에 유리합니다. 비트맵 인덱스는 데이터 웨어하우스에서, 트라이는 문자열 검색에, 그래프 자료구조는 복잡한 관계 모델링에 적합합니다. 또한, LSM 트리, 컬럼형 저장 구조, 인메모리 데이터 구조, 데이터 파티셔닝 및 샤딩과 같은 자료구조들도 특정 요구사항에 맞춰 데이터베이스 성능을 최적화하는 데 중요한 역할을 합니다.
효율적인 데이터 관리와 빠른 응답 속도를 위해서는 단순히 자료구조를 이해하는 것에 그치지 않고, 실제 사용 환경과 요구사항에 맞춰 적절한 자료구조를 선택하고 구현하는 것이 필수적입니다. 데이터의 크기, 쿼리 패턴, 업데이트 빈도, 저장 공간 제한 등 다양한 요소를 종합적으로 고려하여 최적의 자료구조를 선택해야 데이터베이스의 성능을 극대화할 수 있습니다.
정리하자면, 데이터베이스 설계 시 자료구조 선택은 성능 최적화의 핵심 요소 중 하나입니다. 각 자료구조의 특성과 활용 사례를 깊이 있게 이해하고, 실제 요구사항에 맞춰 적절히 적용함으로써 효율적이고 강력한 데이터베이스 시스템을 구축할 수 있습니다.
'개발일지 > 자료구조' 카테고리의 다른 글
| 그래프(Graph): 복잡한 관계를 표현하고 처리하는 자료구조 (0) | 2024.11.17 |
|---|---|
| 이진 트리(Binary Tree)와 이진 탐색 트리(Binary Search Tree): 효율적인 데이터 구조와 검색 (1) | 2024.11.16 |
| 해시 테이블(Hash Table)과 딕셔너리(Dictionary): 빠른 데이터 검색과 저장 (1) | 2024.11.15 |
| 큐(Queue)와 우선순위 큐(Priority Queue): 효율적인 선입선출 및 우선순위 관리 (4) | 2024.11.14 |
| 스택(Stack): 효율적인 후입선출 데이터 관리 (0) | 2024.11.13 |



